Python基础
Python介绍
1989年, 吉多范罗苏姆在圣诞节的假期决心开发一个新的解释器程序, 即python的雏形, 历经2年时间, 1991年, 第一个python解释器程序诞生。python的名字来自于吉多喜爱的电视"Monty pyhton's Flying Circus"。
python的优点:
- 简单易学
- 开发效率高
- 适用面广泛
开发时常见问题:
python不是内部或外部命令: 在安装python的时候, 未勾选Add Python 3.xx to PATHSyntaxError: invalid character: 标点符号写成了中文符号
基础语法
字面量
直接在代码中表示固定值的符号或文本, 称之为字面量。字面量用于表示特定类型的值, 无需通过变量或计算来获取。
# 示例
#整数字面量:
int x = 10
# 浮点数字面量:
float y = 3.14
# 布尔字面量:
bool flag = True
# 数组字面量:
list arr[] = [1, 2, 3]
# 对象字面量:
dict obj = { name: "Alice", age: 25 }常见的字面量类型有:
| 目录 | 特点 | 描述 |
|---|---|---|
| 列表(List) | 有序的可变序列 | Python中使用最频繁的数据类型, 可有序记录一堆数据 |
| 元组(Tuple) | 有序的不可变序列 | 可有序记录一堆不可变Python数据 |
| 集合(Set) | 无序的不重复集合 | 可无序记录一堆不重复的Pyhon数据 |
| 字典(Dictionary) | 无序的Key-Value集合 | 可无序记录一堆Key-Value型的Python数据 |
| 数字(Number) | 浮点数(float):13.14, -13.14 复数(complex):4+3j, 以j结尾代表复数 布尔(bool):True, False, 首字母大写 整数(int):10, -10 |
注释
在编程中规范使用注释可以大大增加程序的可读性, python中有两种注释方法:
- 单行注释: 以
#开头 - 多行注释:
"""注释内容可以换行"""
变量
在程序运行时, 能储存计算结果或能表示值的抽象概念。简单来说, 变量就是在程序运行时, 记录数据的载体。特点是变量的值可以改变。变量的定义格式: 变量名 = 变量值
数据类型
python中使用type(变量名)方法可查看数据类型:
x = 42
print(type(x)) # 输出: <class 'int'>python中变量本身无类型, 是变量存储的数据有类型。打个比方来说, 变量相当于盒子, 数据相当于里面的篮球或足球...
数据类型转换
int(x): 将变量x转换为一个整数float(x): 将变量x转换为一个浮点数str(x): 将变量x转换为一个字符串
标识符
用户在编程时所使用的用于给变量、类、方法命名的一系列名字统称为标识符
python中标识符的命名规则如下:
- 内容限定: 只包含中文、英文、数字、下划线
_, 其中数字不能作为开头。 - 大小写敏感
- 不可使用python中的关键字如"class", "print"等
变量的命名规范应遵循如下约定:
- 见名知意
- 下划线命名法: 多个单词组合变量名, 应使用下划线分隔
- 英文字母全小写
运算符
算术运算符:
+ - * /: 加减乘除
// : 地板除(向下取整), 如9.0 // 2.0 = 4.0 ;9 // 2 = 4
% : 取余数, 如5 % 3 = 2
** : 指数, a**b 表示为a的b次方
赋值运算符:=
复合赋值运算符: += -= *= /= %= **= //=
数字精度控制
使用 %m.n 控制数据的宽度m和精度n:
%5d表示整数的宽度控制在5位, 少则前补空格多则截断, 如数字11会变成[空格][空格][空格]11%5.2f表示将宽度控制为5, 将小数保留2位。
注意:小数点和小数部分也纳入宽度计算。如, 对11.345设置%7.2f后, 结果是:[空格][空格]11.35。先小数部分四舍五入保留2位, 再2个空格补足宽度。%.2f表示不限制宽度, 只保留两位小数。
如果m比数字本身宽度小, 则m不生效。n做精度控制时会四舍五入。
数据输入
使用input()从键盘获取输入, 返回类型默认str
input("请输入您的姓名")逻辑判断
- 使用比较运算符来计算真假:
==,!=,>,<,>=,<= - 使用bool类型表示真假:
TrueorFalse
if 语句基本格式
if 要判断的条件:
条件成立时, 要执行的操作if-else 语句
if 条件:
代码1
else:
代码2if-elif-else 语句
if 条件1:
代码1
elif 条件2:
代码2
elif 条件n:
代码n
else:
else代码循环语句
while 循环
- 基础语法
i=0
while i < 100:
print("hello world!")
i++- 嵌套使用
# while嵌套实现九九乘法表
i=1 # 控制行
while i<10:
j=1 # 控制列
while j<=i:
print(f"{i}*{j}={i*j} \t", end = '')
j++
i++
print(\n)for 循环
- 基础语法
for 临时变量 in 数据集:
满足条件时执行代码- 变量作用域: for中的临时变量只在for循环内部有效
- 嵌套使用
# for嵌套实现九九乘法表
for i in range(1,10):
for j in range(1,i+1):
print(f"{i}*{j}={i*j}\t" ,end='')
print("\n")range()函数
| 使用方式 | 结果 |
|---|---|
range(num) | 获取一个从0开始, 到num结束的数字序列(不含num本身)如, range(5) 取得的数据是: [0, 1, 2, 3, 4] |
range(num1,num2) | 获得一个从num1开始, 到num2结束的数字序列(不含num2本身)如, range(5, 10) 取得的数据是: [5, 6, 7, 8, 9] |
range(num1,num2,step) | 获得一个从num1开始, 到num2结束的数字序列(不含num2本身)数字之间的步长, 以step为准(step默认为1)如, range(5, 10, 2) 取得的数据是: [5, 7, 9] |
循环中断
continue :
- 中断本次循环, 进入下一次循环
- 在嵌套循环中,
continue只在它所在的循环生效
break:
- 直接结束本次循环
- 在嵌套循环中,
break也只在它所在的循环生效
函数
组织好的, 可重复使用的, 用来实现特定功能的代码段叫做函数
基础使用
def 函数名(传入参数):
函数体
return 返回值
# 如果没有返回值, 则默认返回None, 数据类型是 Nonetype函数说明文档
def add(x, y):
"""
计算两数之和
params:
x(int or folat): 第一个数
y(int or folat): 第二个数
return:
(int or float): 两束之和
example:
>>> add(3, 5)
8
>>> add(2.5, 4.5)
7.0
"""
函数体
return 返回值函数的嵌套调用
语句在函数A中执行到函数B的语句, 会将函数B全部执行完成后, 才继续执行函数A的剩余内容
变量的作用域
- 局部变量 : 定义在函数体内部的变量, 只在函数体内部生效, 在函数执行完毕后会销毁
- 全局变量 : 在函数体内、外都能生效的变量; 使用
global关键字在函数内部对全局变量进行修改
多返回值
当函数需要多返回值时, 遵循以下规范:
- 多个返回值用逗号隔开
- 使用多个变量接收多个返回值, 变量用逗号隔开
- 支持不同类型的数据同时return
def test_return():
return 1,2
x, y = test_return()函数参数类型
位置参数(常用)
调用时根据位置传递实参, 要求传递的实参与形参列表的位置和数量必须一致
def user_info(name, age, gender):
print(f'您的名字是 {name}, 年龄是{age}, 性别是{gender}')
user_info('Tom', 20, '男')关键字参数(命名参数)
调用函数时通过键=值 的形式传递实参, 不仅清晰易读而且消除了顺序顾虑。
注意:命名参数与位置参数混用时, 位置参数必须在前
def user_info(name, age, gender):
print(f'您的名字是 {name}, 年龄是{age}, 性别是{gender}')
user_info(name='小明', age=23, gender='男')缺省参数(默认值参数)
定义函数时可为形参提供默认值, 如果调用时没有传入对应实参, 则使用默认值。
def user_info(name = '张三', age = '16', gender = '男'):
print(f'您的名字是 {name}, 年龄是{age}, 性别是{gender}')不定长参数(可变参数)
- 位置传参不定长
# 参数列表中使用*关键字, agrs是元组(tuple)类型,
# 传进的所有参数会作为args的元素被收集起来
def user_info(*args):
print(args)
user_info('TOM')
user_info('TOM', 18)- 关键字传参不定长
# 参数列表使用**关键字, kwargs是字典(dict)类型,
# 会根据传入的键值组成字典
def user_info(**kwargs):
print(kwargs)
user_info(name='TOM', age = 18, id = 110)函数作为参数(回调函数)
回调函数是一种计算逻辑的传递, 而非数据的传递
def test_func(compute):
result = compute(1, 2)
print(result)
def compute(x, y):
return x + y
test_func(compute)lambda函数作为参数(匿名参数)
def test_func(compute):
result = compute(1, 2)
print(result)
test_func(lambda x, y: x + y)
# lambda x, y: x + y 与以下compute函数功能完全相同
# def compute(x, y):
# return x + y数据容器
序列与序列切片
内容连续、有序、可使用下标索引的一类数据容器统称为序列, 如列表, 元组, 字符串都是序列
序列的切片操作:序列[起始下标:结束下标:步长] 表示在序列中, 从指定位置开始, 依次取出元素, 到指定位置结束, 不包含结束下标。得到一个新序列。
- 起始下标:切片开始的位置, 留空则从头开始
- 结束下标:切片结束的位置, 留空则截取到结尾
- 步长:取元素时的间隔, 默认为
1步长 = 1:一个一个取(默认)步长 = 2:每次跳过一个元素取步长 = n:每次跳过n-1个元素取
步长为负数表示反向截取, 此时必须起始下标 > 结束下标(不包含结束下标), 如:str[5:1:-2] 表示从下标5截取到下标1(不含下标1), 并且步长为2的子串
小技巧 :
str[::-1]可以实现对str的反转
List(列表)
python中, list是一种重要数据结构, 用于存储一系列有序的, 可修改的元素
# 使用以下两种方式创建空列表
list_name = []
list_name = list()
# 可以使用append向列表添加元素
list_name.append(element)python列表是有序表, 因此可以通过下标访问
element = list_name[index]要注意, 下标序号有两种表示方式:
- 从左到右, 下标从
0开始
 2. 从右至左, 下标从
2. 从右至左, 下标从-1开始
 常用方法
常用方法
| 方法 | 描述 |
|---|---|
list.append(element) | 在列表末尾添加元素 |
list.insert(index, element) | 在指定位置插入元素 |
list.remove(element) | 删除列表中的元素 |
list.pop() | 删除并返回列表的最后一个元素 |
list.extend(list2) | 将另一个列表list2中的所有元素添加到列表末尾。 |
list.reverse() | 反转列表中的元素顺序 |
list.sort() | 对列表中的元素进行排序 |
list.copy() | 复制列表 |
list.index(element) | 返回元素在列表中首次出现的位置 |
list.count(element) | 返回元素在列表中出现的次数 |
list.clear() | 清空列表 |
需要注意的是, Python List是动态类型, 列表中的元素可以是任意类型的数据, 可以不止单一类型
Tuple(元组)
Python的tuple是一种固定长度的序列,支持多种数据类型。元组的元素是有序的、不可变的,这保证了数据的安全性。
# 创建一个包含数字的元组
t1 = (1, 2, 3, 4, 5)
# 创建一个包含字符串的元组
t2 = ("apple", "banana", "cherry")
# 创建一个包含不同数据类型的元组
t3 = (1, "apple", [1, 2, 3], (1, 2, 3))元组的元素可以通过下标索引访问。从左至右下标索引从0开始(从右向左从-1开始)。例如:
t1 = (1, 2, 3, 4, 5)
print(t1[0]) # 输出:1
print(t1[1]) # 输出:2
print(t1[2]) # 输出:3
print(t1[-1]) # 输出:5常用方法:
| 方法 | 描述 |
|---|---|
tuple.count(element) | 返回元组中指定元素的出现次数 |
tuple.index(element) | 返回元组中指定元素的首次出现的位置 |
len(tuple_name) | 返回元组的长度(元素个数) |
max(tuple_name) | 返回元组中的最大值, 适用于包含数字的元组。 |
min(tuple_name) | 返回元组中的最小值, 适用于包含数字的元组。 |
tuple(list_name) | 将列表转换为元组 |
元组可以进行解包操作,即将元组中的元素分别赋值给不同的变量。这在处理多个返回值的函数时非常有用:
t = (1, 2, 3)
a, b, c = t
print(a, b, c) # 输出:1 2 3元组可以作为字典的键,这在处理键值对时非常有用。例如:
d = {(1, 2): "apple", (3, 4): "banana"}
print(d[(1, 2)]) # 输出:applestr(字符串)
Python中的str(字符串)是一种基本的数据类型,用于表示和处理有序的、不可修改的文本数据
# 使用单引号创建字符串
str1 = 'Hello,world!'
# 使用双引号创建字符串
str2 = "Hello,world!"
# 使用三引号创建字符串(可以包含多行文本)
str3 = """
Hello,
world!
"""字符串的每个字符都有一个对应的下标,从左到右下标从0开始(从右到左下标从-1开始)。可以通过下标访问字符串中的字符。
# 访问字符串中的字符
str1 = 'Hello,world!'
print(str1[0]) # 输出 'H'
print(str1[5]) # 输出 ','常用操作:
- 检查是否以指定子串开头或结尾
# 使用startswith()、endswith()方法检查字符串是否以指定子串开头或结尾
# 使用 startswith() 方法
str1 = 'Hello, world!'
result = str1.startswith('Hello')
print(result) # 输出 True
# 使用 endswith() 方法
str1 = 'Hello, world!'
result = str1.endswith('world!')
print(result) # 输出 True- 格式化字符串
# 可以使用format()方法或f-string(自Python 3.6起)格式化字符串
# 使用 format() 方法
str1 = 'Hello, {}. You are {} years old.'.format('Alice', 30)
print(str1) # 输出 'Hello, Alice. You are 30 years old.'
# 使用 f-string
str1 = f'Hello, {name}. You are {age} years old.'
print(str1) # 输出 'Hello, Alice. You are 30 years old.'
# 在字符串前加 r 前缀, 可以将其标记为原始字符串, 此时反斜杠 \ 不会被转义。
path = r"C:\path\to\file"
print(path) # 输出: C:\path\to\file
name = "Alice"
message = rf"Hello, {name}!\nThis is a raw string."
print(message)
# 输出: Hello, Alice!\nThis is a raw string.- 字符串的编码与解码(重要):
# 使用encode()将字符串转换为字节(二进制)
str1 = 'Hello,world!'
byte1 = str1.encode('utf-8') # 默认使用 UTF-8 编码
print(byte1) # 输出 b'Hello, world!'
# 使用decode()将字节(二进制)转换为字符串
byte1 = b'Hello, world!'
str1 = byte1.decode('utf-8') # 默认使用 UTF-8 编码
print(str1) # 输出 'Hello, world!'
# 编码解码后的字符串是一样的
str1 = 'Hello,world!'
byte1 = b'Hello, world!'
byte1 = str1.encode('utf-8') # 编码
str2 = byte1.decode('utf-8') # 解码
print(str1 == str2) # 输出 True常用方法:
# 创建一个字符串
str1 = "Hello,world!"
# 将字符串转换为大写
str1_upper = str1.upper()
print(str1_upper) # 输出:HELLO,WORLD!
# 将字符串转换为小写
str1_lower = str1.lower()
print(str1_lower) # 输出:hello,world!
# 将字符串中的'o'子串替换为'0'子串
str1_replace = str1.replace('o', '0')
print(str1_replace) # 输出:Hell0,W0rld!
# 将字符串按照','分隔符分割成列表
str1_split = str1.split(',')
print(str1_split) # 输出:['Hello', 'World!']
# 查找'o'子串在字符串中首次出现的位置
str1_find = str1.find('o')
print(str1_find) # 输出:4
# 查找'o'子串在字符串中最后一次出现的位置
str1_rfind = str1.rfind('o')
print(str1_rfind) # 输出:7
# 删除字符串两端的'o'字符
str1_strip = str1.strip('o')
print(str1_strip) # 输出:Hell,Wrld!
# 删除字符串左边的'H'字符
str1_lstrip = str1.lstrip('H')
print(str1_lstrip) # 输出:ello,World!
# 删除字符串右边的'!'字符
str1_rstrip = str1.rstrip('!')
print(str1_rstrip) # 输出:Hello,world
# 将'Hello'和'World'连接成字符串,元素之间用空格连接
str1_join = ' '.join(['Hello', 'World'])
print(str1_join) # 输出:Hello Worldset(集合)
Python中的set是一种无序的不可变的集合,它存储的元素不可重复,可以通过哈希值来快速查找元素。
s = set() # 创建一个空的set对象
s = {1, 2, 3} # 创建一个包含1, 2, 3的set特点
- 无序: set中的元素没有固定的顺序,每次访问时,元素的顺序可能不同。
- 不可变:set中的元素一旦添加,就不能修改。
- 唯一性:set中的元素是唯一的,不允许重复。 常用方法
| 方法 | 描述 |
|---|---|
set.add(element) | 添加一个元素到集合 |
set.clear() | 清除集合中的所有元 |
set.copy() | 返回一个新的set对象,包含与原集合相同的元素 |
set.discard(element) | 删除集合中的一个元素,如果元素不存在,则不执行任何操作 |
set.pop() | 随机删除并返回一个集合中的元素 |
set.remove(element) | 删除集合中的一个元素,如果元素不存在,则引发KeyError |
set1.union(set2) | 返回一个新集合,包含set1与set2的并集 |
set1.update(set2) | 更新set1,使其包含set1与set2的并集 |
dict(字典)
Python中的dict是一种无序的数据结构,用于存储键值对(key-value pairs)
# 使用花括号{}定义字典
dict1 = {"key1": "value1", "key2": "value2"}
# 使用dict()函数定义字典
dict2 = dict({"key1": "value1", "key2": "value2"})特点
- 键的唯一性:字典中的键必须是唯一的。如果尝试将重复的键插入字典,新的值会覆盖旧的值。
- 可变性:字典的键和值都是可变的,也就是说,可以修改字典中的键和值
- 无序性:字典中元素的顺序是随机的,没有固定的顺序
索引方式
可以通过键来访问字典中的值
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# 访问值
print(my_dict['name']) # 输出: John
print(my_dict['age']) # 输出: 30常用操作
- 元素的增添、修改、删除
# 修改字典中的值
dict1['key1'] = "new_value1"
print(dict1["key1"]) # 输出:new_value1
# 添加新的键值对
dict1['key3'] = "value3"
print(dict1) # 输出:{'key1': 'new_value1', 'key2': 'value2', 'key3': 'value3'}
# 删除键值对
del dict1['key1']
print(dict1) # 输出:{'key2': 'value2', 'key3': 'value3'}
# 使用clear()方法清空字典
dict1.clear()
print(dict1) # 输出:{}- 遍历字典
# 可以通过遍历字典的键、值和键值对来访问字典中的元素
# 遍历键
for key in dict1:
print(key)
# 遍历值
for value in dict1.values():
print(value)
# 遍历键值对
for key, value in dict1.items():
print(key, value)- 字典推导式
# 字典推导式是一种简洁高效的创建字典的方式
dict3 = {i: i**2 for i in range(1, 10)}
print(dict3) # 输出:{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}- 字典的解包
dict5 = {"key1": "value1", "key2": "value2"}
key, value = dict5
print(key, value) # 输出:key1 value1- 字典的复制 在Python中,字典的复制分为浅拷贝和深拷贝。浅拷贝会创建一个新的字典,但其中的值仍然是对原始字典中值的引用,动其中任何一个字典则另外字典也会改变。深拷贝会创建一个新的字典,其中所有的值都是对原始字典中值的副本,两个字典互相独立。
dict7 = {"key1": "value1", "key2": {"subkey": "subvalue"}}
dict8 = dict7.copy() # 浅拷贝
dict9 = dict7.deepcopy() # 深拷贝
dict7["key2"]["subkey"] = "new_subvalue"
print(dict8) # 输出:{'key1': 'value1', 'key2': {'subkey': 'new_subvalue'}}
print(dict9) # 输出:{'key1': 'value1', 'key2': {'subkey': 'subvalue'}}- 字典的合并
# 可以使用update()方法将两个或多个字典合并
dict10 = {"key1": "value1"}
dict11 = {"key2": "value2"}
dict10.update(dict11)
print(dict10) # 输出:{'key1': 'value1', 'key2': 'value2'}- 字典的遍历
# 字典的遍历可以通过多种方式实现,例如使用for循环、items()方法或enumerate()方法
dict12 = {"key1": "value1", "key2": "value2"}
for key in dict12:
print(key, dict12[key]) # 输出:key1 value1, key2 value2
for key, value in dict12.items():
print(key, value) # 输出:key1 value1, key2 value2
for i, (key, value) in enumerate(dict12.items()):
print(i, key, value) # 输出:0 key1 value1, 1 key2 value2总结
数据容器可以分为以下两种类型:
序列类型(支持下标索引、支持元素重复)
| 数据容器 | 是否可修改 |
|---|---|
list | 可修改 |
Tuple | 不可修改 |
str | 不可修改 |
非序列类型(不支持下标索引、不支持元素重复)
| 数据容器 | 是否可修改 |
|---|---|
set | 可修改 |
dict | 可修改 |
五类容器都支持for遍历,但只有列表list、元组Tuple、字符串str支持while循环(因为集合、字典是无序的,无法使用下标索引)
文件操作
打开文件
使用open()函数打开文件,语法为:
file = open('filename', 'mode')
# filename: 文件路径
# mode:打开模式,常见的有:
# 'r':只读(默认)。
# 'w':写入,覆盖文件(如果文件不存在则新建文件)。
# 'a':追加,写入到文件末尾。
# 'b':二进制模式,如'rb'或'wb'。
# 'x':创建新文件,若文件存在则报错。
# '+':读写模式,如'r+'。读取文件
file.read(num):读取全部内容。num表示要从文件中读取的数据的长度(单位:字节),不传入则读取文件中所有数据。file.readline():读取一行。file.readlines():读取所有行并返回列表。还可以使用for循环读取文件
for line in open("C:/Users/xxx/Desktop/test.txt", "r")
print(line)写文件
file.write():写入字符串file.writelines():写入字符串列表。file.flush(): 内容刷新
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区,当调用flush()的时候,内容会真正写入文件。 这样做是避免频繁操作硬盘,导致效率下降(攒一堆,一次性写入)。
关闭文件
file.close(): 此方法内置flush()功能
使用with操作
with语句能自动处理文件的打开和关闭, 推荐使用:
with open('example.txt', 'r') as file:
content = file.read()
print(content)Python异常捕获
当异常发生时,程序会抛出异常并停止执行,除非进行异常处理。 捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。避免因为一个小bug就让整个程序崩溃,希望对小bug进行提醒,让整个程序继续进行
捕获常规异常
try:
可能发生错误的代码
except Exception as e:
try代码出错就执行此部分代码捕获指定异常
try:
可能发生错误的代码
except 指定异常 as e:
try代码出错就执行此部分代码这些指定异常有:
| 异常 | 描述 | 原因 |
|---|---|---|
SyntaxError | 语法错误 | 代码编写错误,不符合 Python 语法规则 |
IndentationError | 缩进错误 | 代码缩进不正确,例如缩进空格数不匹配 |
NameError | 名称错误 | 使用了未定义的变量或函数名 |
TypeError | 类型错误 | 操作或函数应用于了错误的数据类型 |
IndexError | 索引错误 | 尝试访问列表、元组或字符串等中不存在的索引 |
KeyError | 键错误 | 尝试使用字典中不存在的键 |
ValueError | 数值错误 | 函数接收到的参数类型正确但值不合适 |
FileNotFoundError | 文件未找到错误 | 尝试打开不存在的文件 |
ZeroDivisionError | 除零错误 | 尝试除以零 |
AssertionError | 断言错误 | 使用 assert 语句发生错误,表明某个条件为假 |
捕获多个异常
try:
可能发生错误的代码
except (指定异常1, 指定异常2, ...) as e:
代码出错执行此部分代码异常的else和finally用法
try:
可能发生错误的代码
except:
代码出错就执行此部分代码
else:
代码没出错就执行此部分代码
finally:
无论是否出现异常, 都要执行此处代码python模块(module)
模块就是一个封装好的Python文件,里面有类、函数、变量等,我们可以在任何有需要的时候直接导入使用。 我们可以认为一个模块就是一个工具包,每一个工具包中都有各种不同的工具供我们使用,从而实现各种不同的功能
模块的导入
# 模块使用前需要先导入 导入的语法如下:
[from 模块名] import [模块|类|变量|函数|*] [as 别名]
# 常用的组合形式如:
import 模块名
from 模块名 import 类、变量、方法等
from 模块名 import *
import 模块名 as 别名
from 模块名 import 功能名 as 别名# import time 与 from time import * 的区别在于包中内容调用时的写法不同:
import time
# 调用时
time.sleep(5)
from time import *
# 调用时
sleep(5)自定义模块
每个Python文件都可以作为一个模块供另外一个文件去import使用,模块的名字就是文件名,因此,自定义python文件必须要符合标识符命名规则
注意:当导入多个模块中有同名方法时,后导入的模块会将前面导入模块中的同名方法覆盖,此时如果调用,使用的是后导入的模块的方法
在实际开发中,当一个开发人员编写玩一个模块后,开发规范会要求他在这个模块中的main中添加测试代码`
# mymodule.py
__all__:['add']
# 当使用 from xxx import * 导入时,只能导入这个字符串列表中标明的元素
# from xxx import * , * 的含义就是这个变量_ _all_ _;
# from xxx import 方法名 可以跳过_ _all_ _去调用模块中的各种方法
def add(a, b):
return a + b
def reduce(a, b):
return a + b
def test(a, b):
sum = add(1, 2)
differ =reduce(4, 1)
if __name__ == "__main__":
# 此部分在当前文件作为主程序运行时执行,但是当其他文件引用这个模块时,
# 这部分代码块将不会被执行。
# 这个结构经常用于编写可执行的脚本代码,或者用于测试模块时执行一些特定代码。
test()Python包(Package)
将若干个模块放在一个文件夹下并添加__init__.py文件, 文件夹就成为了包(Package) 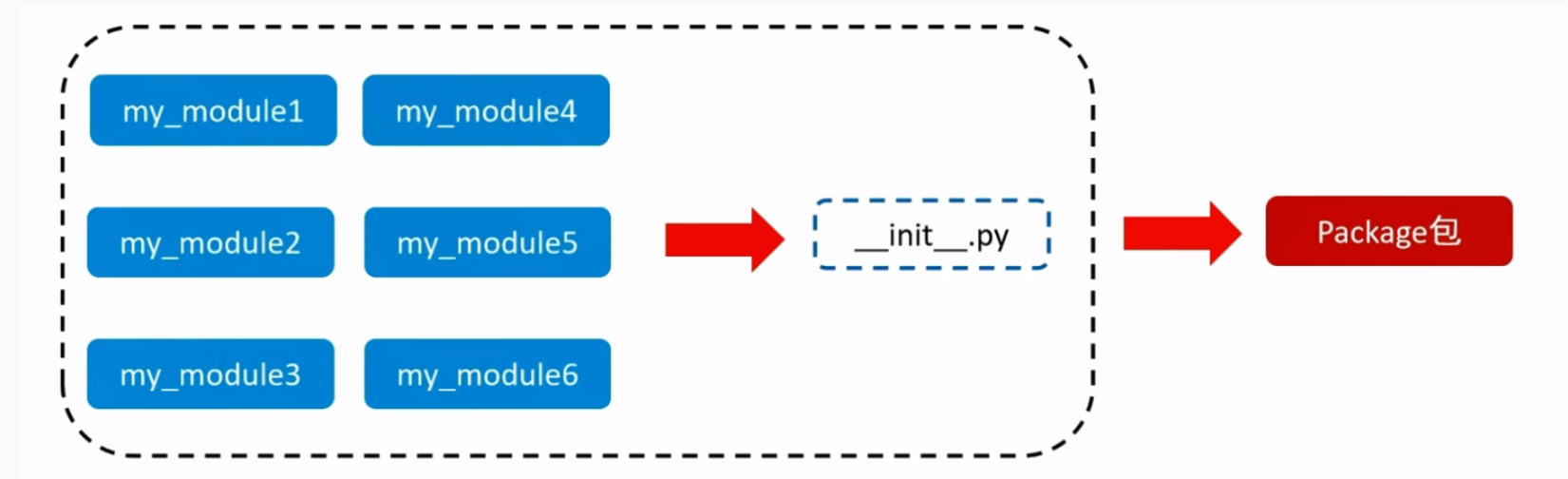
- 注意: 必须在
__init__.py中定义__all__变量用来控制import *的行为。在包中,__all__变量中指定的是包的模块文件名而不是模块中的方法名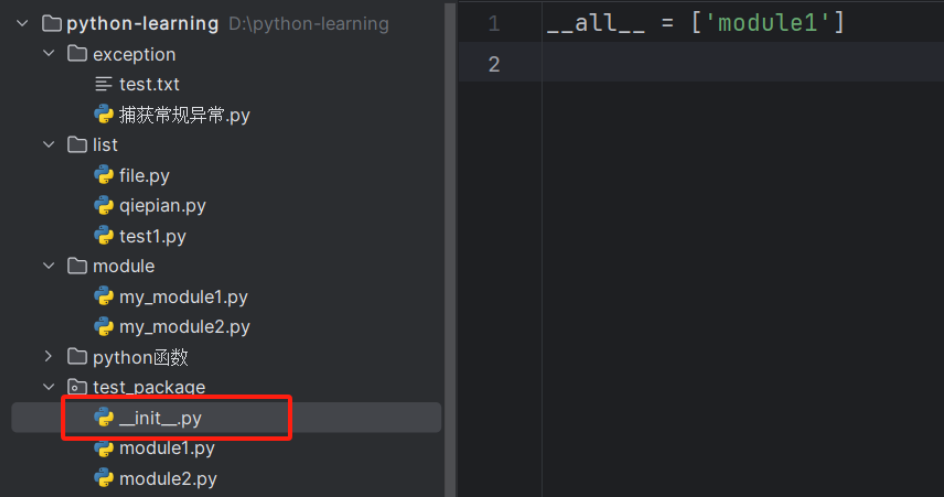
导入包
# 1.import 包名.模块名
import my_package.module1
import my_package.module2
my_package.module1.printInfo()
my_package.module2.printInfo()
# 2.
# from 包名 import 模块1, 模块2...
# from 包名 import * (导入的是__all__中的模块)
from my_package import module1
module1.printInfo()局部安装第三方包
- 终端进入当前项目目录
- 使用命令为当前项目创建一个名为
venv的虚拟环境:
python -m venv .- 创建完成后会多出来三个文件夹
Include,Lib,Scripts和一个pyvenv.cfg文件。输入以下命令激活当前虚拟环境:
\Scripts\activate- 在当前项目下安装需要的第三方包, 此时第三方包会下载至
当前项目/Lib/site-package文件夹中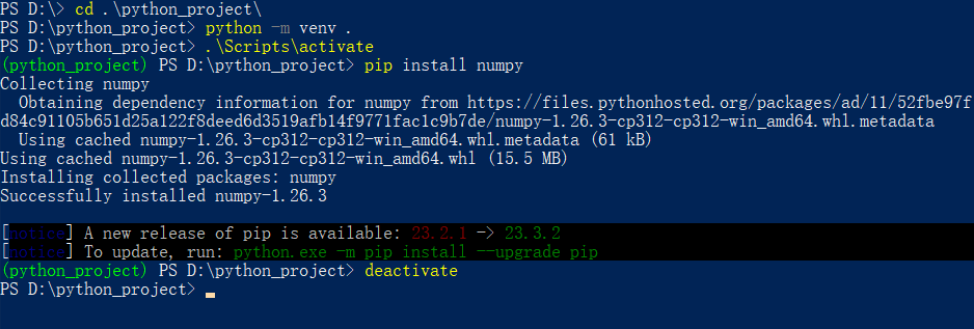
- 输入以下命令返回全局
Python环境
deactivate- 注意: 全局安装的
python包会被下载至python安装路径\Lib\site-packages中
python常用包:
| 领域 | 包名 |
|---|---|
| 数据分析三剑客 | numpy + pandas + matplotlib |
| 大数据计算 | pyspark, apache-flink |
| 图形可视化 | matplotlib, pyecharts |
| 人工智能 | tensorflow |
类型注解
在调用自定义函数时,IDE无法通过代码确定参数传入的是什么类型,因此无法进行参数提示和自动补全,因此要使用类型注解。类型注解仅仅是提示,不会报错。
变量的类型注解
- 基础数据类型注解
var_1: int = 10
var_2: float = 3.1415
var_3: bool = True
var_4: str = "hello"- 类对象类型注解
class Student:
pass
stu: Student = Student()- 基础容器类型注解
my_list: list = [1, 2, 3]
my_tuple1: tuple = (1, 2, 3)
my_tuple2: tuple[str, int, bool] = ("jack", 19, True)
my_set1: set = {1, 2, 3}
my_set2: set[int] = {1, 2, 3}
my_dict: dict = {"name": "jack"}
my_dict2: dict[str,int] = {"age": 20}
my_str: str = "hello world"- 在注释中也可以进行类型注解,效果相同
class Student:
pass
var_1 = random.randint(1, 10) # type: int
var_2 = json.loads(data) # type: dict[str, int]
Student = Student() # type: Student函数的类型注解
- 形参注解
def add(x:int, y:int):
return x+y- 返回值注解
def add(x:int, y:int) -> int:
return x+y无规律类型注解(Union)
可以使用Union关键字定义联合注解
from typing import Union
my_list: list[Union[str, int]] = [1, 2, "abc", "123"]
my_dict: dict[Union[str, int], Union[str, int]] = {123: "周杰伦", "age": 31}函数中同样可以使用Union联合注解
from typing import Union
def func(data: Union[int, str]) -> Union[int, str]
return True闭包
在函数嵌套中,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包
def outer(logo):
def inner(msg):
print(f"{logo}{msg}{logo}")
return inner
fn1 = outer("2024") # 调用outer函数, 传入logo = 2024, 返回 inner 函数并赋值给fn1
fn1("新年快乐") # 调用 fn1(即 inner 函数),传入 msg = "新年快乐",执行 inner 函数
# 最终输出: 2024新年快乐2024nonlocal关键字
如果内部函数需要修改外部函数的变量,则需要nonlocal关键字
def outer(num1):
def inner(num2):
nonlocal num1
num1 += num2
print(num1)
return inner
fn1 = outer(10) # 调用 outer 函数,传入 num1 = 10,返回 inner 函数并赋值给 fn1
fn1(20) # 调用 fn1(即 inner 函数),传入 num2 = 20,执行 inner 函数内部的逻辑优缺点分析
优点:
- 无需定义全局变量即可实现函数持续的访问、修改某个值
- 闭包使用的变量的作用域是在函数内,难以被错误地调用和修改
缺点:
- 由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用着内存(优化重点)
装饰器
装饰器其实也是一种闭包,其功能就是在不破坏目标函数原有代码的功能的前提下,为目标函数增加新功能
# 方式1: 定义一个闭包函数, 在闭包函数内部执行目标函数, 并完成新功能的添加
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
def sleep():
import random
import time
print("睡眠中....")
time.sleep(random.randint(1, 5))
fn = outer(sleep)
fn()
# 执行结果:
# 我要睡觉了
# 睡眠中....
# 我起床了# 方式2: 使用语法糖
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
@outer
def sleep():
import random
import time
print("睡眠中....")
time.sleep(random.randint(1, 5))
sleep()设计模式
工厂模式
- 工厂模式的核心思想是将对象的创建逻辑封装在一个单独的工厂类中,客户端代码只需要与工厂类交互,而不需要直接实例化具体的类。
- 当对象的创建过程涉及多个步骤或依赖外部配置时,可以使用工厂模式封装这些逻辑
- 需要修改时仅修改工厂类的创建方法即可
# 定义支付接口(抽象类)
class Payment():
def pay(self, amount: float) -> None:
pass
# 具体支付类:支付宝支付
class Alipay(Payment):
def pay(self, amount: float) -> None:
print(f"使用支付宝支付 {amount} 元")
# 具体支付类:微信支付
class WechatPay(Payment):
def pay(self, amount: float) -> None:
print(f"使用微信支付 {amount} 元")
# 具体支付类:银行卡支付
class BankCardPay(Payment):
def pay(self, amount: float) -> None:
print(f"使用银行卡支付 {amount} 元")
# 支付工厂类
class PaymentFactory:
@staticmethod
def create_payment(method: str) -> Payment:
if method == "alipay":
return Alipay()
elif method == "wechatpay":
return WechatPay()
elif method == "bankcard":
return BankCardPay()
else:
raise ValueError(f"不支持的支付方式: {method}")
# 客户端代码
def main():
# 通过工厂创建支付对象
payment_method = "alipay" # 可以是 "alipay", "wechatpay", "bankcard"
payment = PaymentFactory.create_payment(payment_method)
payment.pay(100.0)
if __name__ == "__main__":
main()
# 客户端只需要与工厂类交互,无需知道具体支付类的实现细节。
# 添加新的支付方式时,只需要新增具体类和修改工厂类,无需修改客户端代码。
# 对象的创建逻辑集中在工厂类中,便于维护。单例模式
- 确保一个类只能创建一个实例,节省内存和计算资源
- 提供一个全局访问点,方便其他代码获取该实例
- 单例模式通常用于需要全局唯一对象的场景,例如配置管理、日志记录、数据库连接池等
- python模块是天然的单例模式,我们只需把函数和数据定义放在一个模块中,就可以获得一个单例对象。
mysingleton.py
class Singleton(obj):
def foo(self):
pass
singleton = Singleton()其他文件.py
from mysingleton import singleton
s1 = singleton
s2 = singleton
print(s1) # 输出: 实例1
print(s2) # 输出: 实例1
print(s1 is s2) # 输出: True多线程
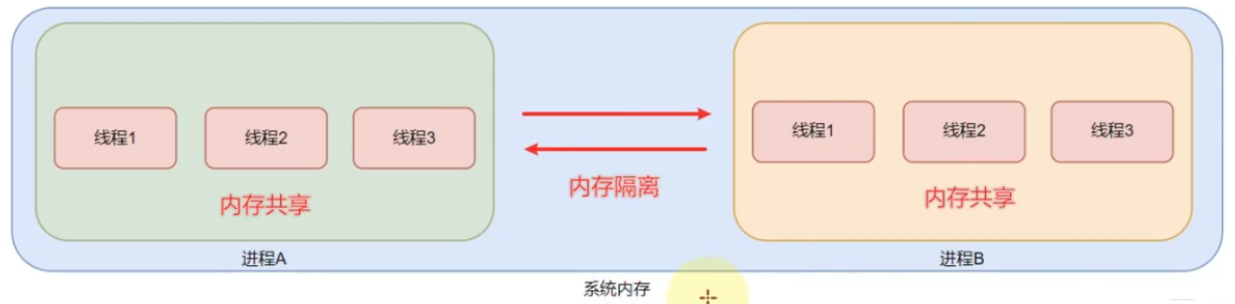
进程和线程
- 运行在系统上的程序都是进程,并且各自有自己的
进程id方便系统管理 - 线程是进程的最小单位,一个进程可以开启多个线程,执行不同的工作
- 不同进程之间是内存隔离的,同一个进程下的线程是内存共享的
- GIL(全局解释器锁):Python 的 GIL 确保同一时间只有一个线程执行 Python 字节码,因此多线程在 CPU 密集型任务中性能提升有限。
多线程编程
Python多线程依赖threading模块实现
import threading
thread_obj = threading.Thread([group[, target, name, args, kwargs]])
"""
创建线程
params:
group: 指定进程组, 无进程组则是None
target: 执行的目标任务名
name: 线程名(可选)
args: 以元组的方式给执行任务传参
kwargs: 以字典方式给执行任务传参
"""
# 启动线程, 让线程开始工作
thread_obj.start()示例1: 直接创建线程
import threading
import time
def task(name):
print(f"任务 {name} 开始")
time.sleep(2) # 模拟耗时操作
print(f"任务 {name} 结束")
# 创建线程
thread1 = threading.Thread(target=task, args=("A",))
thread2 = threading.Thread(target=task, args=("B",))
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
print("所有任务完成")示例2: 继承 threading.Thread 类
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(f"任务 {self.name} 开始")
time.sleep(2) # 模拟耗时操作
print(f"任务 {self.name} 结束")
# 创建线程
thread1 = MyThread("A")
thread2 = MyThread("B")
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
print("所有任务完成")网络编程
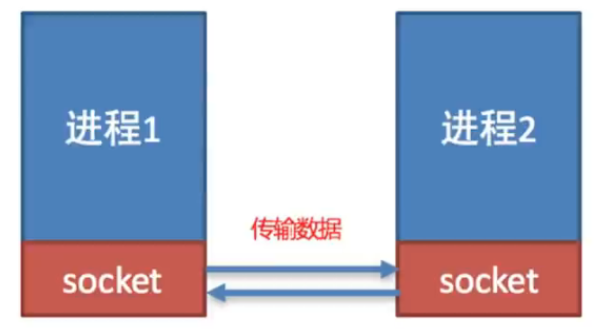
套接字(Socket)
Python 的 socket 模块提供了对网络通信的低级接口,允许你实现网络应用程序,如客户端-服务器模型。 它支持两种主要的协议:
- TCP(传输控制协议) : 面向连接,可靠,基于字节流
- UDP(用户数据报协议) : 无连接,不可靠,基于数据报
TCP Socket编程
- 服务器端:
- 创建Socket。
- 绑定IP地址和端口
- 监听连接
- 接受连接
- 收发消息
- 关闭连接
import socket
# 创建 TCP Socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定ip和端口
server.bind(('127.0.0.1', 8002))
# 设置等待连接人数
server.listen(5)
while True:
# 等待客户端连接
print('Server waiting for connection...')
conn, addr = server.accept()
print(f'Connected by {addr}')
# 接受客户端返回的消息
buf = conn.recv(2048)
print(f'recieve from client: {buf.decode('utf-8')}')
# 向客户端发送消息
# do something...
send_msg = "server: 你好,客户端"
conn.send(send_msg.encode("utf-8"))
# 断开连接
conn.close()
# 停止服务端程序
server.close()- 客户端:
- 创建Socket
- 绑定IP地址和端口
- 接收数据
- 发送数据
- 关闭Socket
import socket
# 创建TCP连接
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 向服务器发送连接请求
client.connect(('127.0.0.1', 8002))
# 向服务端发送消息
send_msg = "client:你好,服务器!"
client.send(send_msg.encode('utf-8'))
# 接收服务端消息
rev_msg = client.recv(1024)
print(f"收到数据: {rev_msg.decode('utf-8')}")
# 断开客户端连接
client.close()UDP Socket编程
- 服务器端:
- 创建Socket
- 绑定IP地址和端口
- 接收数据
- 发送数据
- 关闭套接字
import socket
# 创建 UDP socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定 IP 和 端口
server_socket.bind(('127.0.0.1', 12345))
print("UDP 服务器已启动, 等待数据...")
# 接收数据
data, addr = server_socket.recvfrom(1024)
print(f"收到来自 {addr} 的数据: {data.decode('utf-8')}")
# 发送数据
server_socket.sendto("你好, 客户端!".encode('utf-8'), addr)
# 关闭socket
server_socket.close()- 客户端:
- 创建套接字
- 发送数据
- 接受数据
- 关闭套接字
import socket
# 创建 UDP 套接字
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 发送数据
client_socket.sendto("你好, 服务器!".encode(utf-8), ('127.0.0.1', 12345))
# 接收数据
data, addr = client_socket.recvfrom(1024)
print(f"收到来自 {addr} 的数据: {data.decode{'urf-8'}}")
# 关闭套接字
client_socket.close()正则表达式
Python 的正则表达式通过 re 模块提供支持,用于匹配、查找、替换和分割字符串。
正则表达式由普通字符和特殊字符(元字符)组成。以下是一些常用的元字符:
| 元字符 | 描述 |
|---|---|
. | 匹配任意字符 |
^ | 匹配字符串开头 |
$ | 匹配字符串结尾 |
* | 匹配前一个字符0次或多次 |
+ | 匹配前一个字符1次或多次 |
? | 匹配前一个字符0次或1次 |
{n} | 匹配前一个字符n次 |
{n,} | 匹配前一个字符至少n次 |
{n, m} | 匹配前一个字符至少n次, 至多m次 |
\d | 匹配数字, 等价于[0-9] |
\D | 匹配非数字 |
\w | 匹配字母、数字或下划线(等价于[a-zA-z0-9_]) |
\W | 匹配非字母、数字或下划线 |
\s | 匹配空白字符 |
\S | 匹配非空白字符 |
[] | 匹配括号内任意一个字符 |
` | 匹配左边或右边的表达式 |
() | 分组, 捕获匹配的内容 |
re模块的常用函数
re.match(): 从字符串的开头匹配正则表达式
import re
result = re.match(r'\d+', '123abc')
if result:
print("匹配成功:", result.group()) # 输出: 匹配成功: 123
else:
print("匹配失败")re.search(): 在字符串中搜索匹配正则表达式的第一个位置
import re
result = re.research(r'\d+', 'abc123def')
if result:
print("匹配成功:", result.group()) # 输出: 匹配成功: 123
else:
print("匹配失败")re.findall(): 查找字符串中所有匹配正则表达式的内容, 返回列表
import re
result = re.findall(r'\d+', 'abc123def456')
print(result) # 输出: ['123', '456']re.finditer(): 查找字符串中所有匹配正则表达式的内容, 返回迭代器
import re
result = re.finditer(r'\d+', 'abc123def456')
for match in result:
print(match.group())
# 输出:
# 123
# 456re.sub(): 替换字符串中匹配正则表达式的内容
import re
result = re.sub(r'\d+', 'NUM', 'abc123def456')
print(result) # 输出: abcNUMdefNUMre.split(): 根据正则表达式分割字符串, 返回列表类型
import re
result = re.split(r'\d+', 'abc123def456ghi')
print(result) # 输出: ['abc', 'def', 'ghi']正则表达式的分组
使用()可以将匹配的内容分组, 并通过group()方法获取
import re
result = re.search(r'(\d+)-(\d+)', '电话: 123-456')
if result:
print("完整匹配", result.group()) # 输出: 123-456
print("第一组", result.group(1)) # 输出: 123
print("第二组", result.group(2)) # 输出: 456贪婪匹配与非贪婪匹配
- 贪婪匹配 :
re模块的大部分函数默认为贪婪匹配, 正则表达式会尽可能多地匹配字符 - 非贪婪匹配 : 在量词后加
?, 尽可能少地匹配字符
import re
# 贪婪匹配
result = re.search(r'\d+', '123abc456')
print(result.group()) # 输出: 123
# 非贪婪匹配
result = re.search(r'\d+?', '123abc456')
print(result.group()) # 输出: 1常用正则表达式示例
- 匹配邮箱地址
import re
email = "example@domain.com"
pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
if re.match(pattern, mail):
print("email correct!")
else:
print("email error!")- 匹配手机号码
import re
phone = "13800138000"
pattern = r'^1[3-9]\d{9}$'
if re.match(pattern, phone):
print("phone number correct!")
else:
print("phone number error!")- 提取HTML标签中的内容
import re
html = "<div>内容</div>"
pattern = r'<[^>]+>(.*?)</[^>]+>'
result = re.search(pattern, html)
if result:
print("提取到内容:\n", result.group()) # 输出: 内容注意事项
- 正则表达式的性能可能受模式复杂度的影响,尽量避免过于复杂的模式
- 在处理大量数据时, 建议预编译正则表达式以提高性能:
import re
data = "待匹配的字符串"
pattern = re.compile(r'\d+') # 预编译正则表达式
retult = pattern.findall(data)递归
递归的基本概念
- 递归函数: 一个函数在其定义中调用自身
- 递归条件:
- 基线条件(Base Case): 递归终止的条件, 防止无限递归
- 递归条件(Recursive Case): 将问题分解为更小的子问题, 并调用自身解决
递归的基本结构
def recursive_func(参数):
if 基线条件:
return 基线结果
else:
更新参数
return recursive_func(更新后的参数)递归的经典示例
- 计算阶乘 阶乘的定义是:
n! = n * (n - 1), 其中0! = 1
def factorial(n):
if n == 0: # 基线条件
return 1
else:
return factorial(n * (n-1))- 计算斐波那契数列 斐波那契数列的定义是:
F(n) = F(n-1) + F(n-2), 其中F(0) = 0,F(1) = 1
def fibonacci():
if n == 0:
return 0
elif n == 1:
return 1
else:
return fabonacci(n-1) + fabonacci(n-2)- 遍历目录下的所有文件
- 基线条件: 如果是文件, 打印路径
- 递归条件: 如果是目录, 递归调用
import os
def list_file(path):
for item in os.listdir(path):
full_path = os.path.join(path, item)
if os.path.isdir(full_path): # 如果是目录, 递归调用
list_files(full_path)
else: # 如果是文件, 打印路径
print(full_path)递归的优缺点
优点 :
- 代码简洁: 递归可以用较少的代码解决复杂问题
- 直观: 对于树形结构, 递归的实现更符合问题的自然描述
缺点 :
- 性能问题: 递归可能产生大量的函数调用, 导致栈溢出或效率低下
- 调试困难: 递归的调用链较长时, 调试和跟踪问题可能比较困难
递归的优化
- 尾递归优化
尾递归是指递归调用是函数的最后一步操作。某些编程语言支持尾递归优化, 但Python不支持 - 记忆化
通过缓存已计算的结果, 避免重复计算
def fibonacci(n, memo = {}):
if n in memo: # 如果结果已缓存, 直接返回结果
return memo[n]
if n == 0: # 基线条件
return 0
elif n == 1: # 基线条件
return 1
else: #递归条件
memo[n] = fibonacci(n-1, memo) + fibonacci(n-2, memo)
return memo[n]- 转换为迭代
将递归问题转换为循环问题, 避免栈溢出
def factorial(n):
"""
计算n的阶乘
params:
n(int): 待计算的数
return:
result(int): n的阶乘
"""
result = 1
for i in range(1, n + 1):
result *= i
return result注意事项
- 栈溢出: Python默认的递归深度是1000, 可以通过sys.setrecursionlimit()修改, 但不建议滥用
- 基线条件: 必须确保递归有终止条件, 否则会无限递归
对象自省机制
Python 的对象自省机制是指在运行时动态获取对象信息的能力。通过自省,可以查看对象的类型、属性、方法等信息。
查看对象的类型
使用type()函数可以获取对象的类型
x = 42
print(type(x)) # 输出: <class 'int'>查看对象的所有属性和方法
使用dir()函数可以查看对象的所有属性和方, 返回列表
my_list = [1, 2, 3]
print(dir(my_list)) # 输出: ['__add__', '__class__', '__contains__', ...]使用__dict__属性可以查看对象的所有属性, 返回字典
class MyClass:
def __init__(self):
self.x = 10
self.y = 20
obj = MyClass()
print(obj.__dict__) # 输出: {'x': 10, 'y': 20}检查对象是否包含指定属性或方法
使用hasattr()函数可以检查对象是否包含指定属性或方法
class MyClass:
def __init__(self):
self.value = 10获取对象的属性或方法
使用getattr()函数可以获取对象的属性或方法
class MyClass:
def __init__(self):
self.value = 10
obj = MyClass()
print(getattr(obj, 'value')) # 输出: 10设置对象的属性值
使用setattr()函数可以设置对象的属性值
class MyClass:
def __init__(self):
self.value = 10
obj = MyClass()
setattr(obj, 'value', 20)
print(obj.value) # 输出: 20检查对象是否为某个类的实例
使用isinstance()函数可以检查对象是否为某个类的实例
class MyClass:
pass
obj = MyClass()
print(isinstance(obj, MyClass)) # 输出: True
print(isinstance(obj, str)) # 输出: False检查一个类是否是另一个类的子类
使用issubclass()函数可以检查一个类是否是另一个类的子类
class Parent:
pass
class Child(Parent):
pass
print(issubclass(Child, Parent)) # 输出: True
print(issubclass(Parent, Child)) # 输出: False(end)