Python进阶
类型注解
在调用自定义函数时,IDE无法通过代码确定参数传入的是什么类型,因此无法进行参数提示和自动补全,因此要使用类型注解。类型注解仅仅是提示,不会报错。
变量的类型注解
- 基础数据类型注解
var_1: int = 10
var_2: float = 3.1415
var_3: bool = True
var_4: str = "hello"- 类对象类型注解
class Student:
pass
stu: Student = Student()- 基础容器类型注解
my_list: list = [1, 2, 3]
my_tuple1: tuple = (1, 2, 3)
my_tuple2: tuple[str, int, bool] = ("jack", 19, True)
my_set1: set = {1, 2, 3}
my_set2: set[int] = {1, 2, 3}
my_dict: dict = {"name": "jack"}
my_dict2: dict[str,int] = {"age": 20}
my_str: str = "hello world"- 在注释中也可以进行类型注解,效果相同
class Student:
pass
var_1 = random.randint(1, 10) # type: int
var_2 = json.loads(data) # type: dict[str, int]
Student = Student() # type: Student函数的类型注解
- 形参注解
def add(x:int, y:int):
return x+y- 返回值注解
def add(x:int, y:int) -> int:
return x+y无规律类型注解(Union)
可以使用Union关键字定义联合注解
from typing import Union
my_list: list[Union[str, int]] = [1, 2, "abc", "123"]
my_dict: dict[Union[str, int], Union[str, int]] = {123: "周杰伦", "age": 31}函数中同样可以使用Union联合注解
from typing import Union
def func(data: Union[int, str]) -> Union[int, str]
return True闭包
在函数嵌套中,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包
def outer(logo):
def inner(msg):
print(f"{logo}{msg}{logo}")
return inner
fn1 = outer("2024") # 调用outer函数, 传入logo = 2024, 返回 inner 函数并赋值给fn1
fn1("新年快乐") # 调用 fn1(即 inner 函数),传入 msg = "新年快乐",执行 inner 函数
# 最终输出: 2024新年快乐2024nonlocal关键字
如果内部函数需要修改外部函数的变量,则需要nonlocal关键字
def outer(num1):
def inner(num2):
nonlocal num1
num1 += num2
print(num1)
return inner
fn1 = outer(10) # 调用 outer 函数,传入 num1 = 10,返回 inner 函数并赋值给 fn1
fn1(20) # 调用 fn1(即 inner 函数),传入 num2 = 20,执行 inner 函数内部的逻辑优缺点分析
优点:
- 无需定义全局变量即可实现函数持续的访问、修改某个值
- 闭包使用的变量的作用域是在函数内,难以被错误地调用和修改
缺点:
- 由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用着内存(优化重点)
装饰器
装饰器其实也是一种闭包,其功能就是在不破坏目标函数原有代码的功能的前提下,为目标函数增加新功能
# 方式1: 定义一个闭包函数, 在闭包函数内部执行目标函数, 并完成新功能的添加
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
def sleep():
import random
import time
print("睡眠中....")
time.sleep(random.randint(1, 5))
fn = outer(sleep)
fn()
# 执行结果:
# 我要睡觉了
# 睡眠中....
# 我起床了# 方式2: 使用语法糖
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
@outer
def sleep():
import random
import time
print("睡眠中....")
time.sleep(random.randint(1, 5))
sleep()设计模式
工厂模式
- 工厂模式的核心思想是将对象的创建逻辑封装在一个单独的工厂类中,客户端代码只需要与工厂类交互,而不需要直接实例化具体的类。
- 当对象的创建过程涉及多个步骤或依赖外部配置时,可以使用工厂模式封装这些逻辑
- 需要修改时仅修改工厂类的创建方法即可
# 定义支付接口(抽象类)
class Payment():
def pay(self, amount: float) -> None:
pass
# 具体支付类:支付宝支付
class Alipay(Payment):
def pay(self, amount: float) -> None:
print(f"使用支付宝支付 {amount} 元")
# 具体支付类:微信支付
class WechatPay(Payment):
def pay(self, amount: float) -> None:
print(f"使用微信支付 {amount} 元")
# 具体支付类:银行卡支付
class BankCardPay(Payment):
def pay(self, amount: float) -> None:
print(f"使用银行卡支付 {amount} 元")
# 支付工厂类
class PaymentFactory:
@staticmethod
def create_payment(method: str) -> Payment:
if method == "alipay":
return Alipay()
elif method == "wechatpay":
return WechatPay()
elif method == "bankcard":
return BankCardPay()
else:
raise ValueError(f"不支持的支付方式: {method}")
# 客户端代码
def main():
# 通过工厂创建支付对象
payment_method = "alipay" # 可以是 "alipay", "wechatpay", "bankcard"
payment = PaymentFactory.create_payment(payment_method)
payment.pay(100.0)
if __name__ == "__main__":
main()
# 客户端只需要与工厂类交互,无需知道具体支付类的实现细节。
# 添加新的支付方式时,只需要新增具体类和修改工厂类,无需修改客户端代码。
# 对象的创建逻辑集中在工厂类中,便于维护。单例模式
- 确保一个类只能创建一个实例,节省内存和计算资源
- 提供一个全局访问点,方便其他代码获取该实例
- 单例模式通常用于需要全局唯一对象的场景,例如配置管理、日志记录、数据库连接池等
- python模块是天然的单例模式,我们只需把函数和数据定义放在一个模块中,就可以获得一个单例对象。
mysingleton.py
class Singleton(obj):
def foo(self):
pass
singleton = Singleton()其他文件.py
from mysingleton import singleton
s1 = singleton
s2 = singleton
print(s1) # 输出: 实例1
print(s2) # 输出: 实例1
print(s1 is s2) # 输出: True多线程
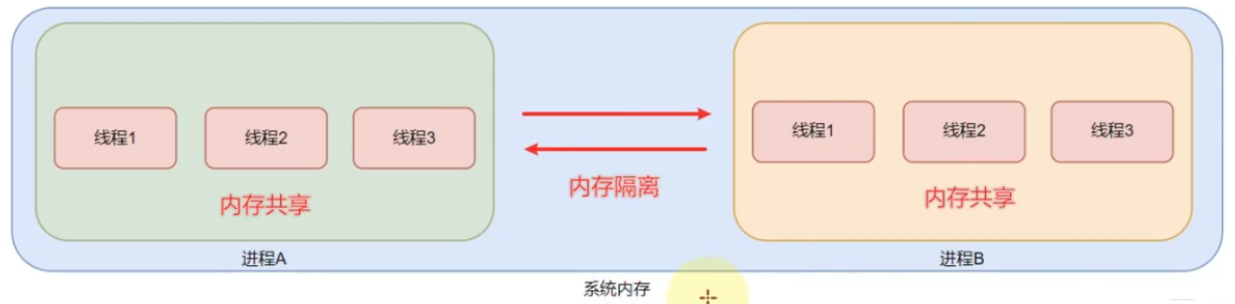
进程和线程
- 运行在系统上的程序都是进程,并且各自有自己的
进程id方便系统管理 - 线程是进程的最小单位,一个进程可以开启多个线程,执行不同的工作
- 不同进程之间是内存隔离的,同一个进程下的线程是内存共享的
- GIL(全局解释器锁):Python 的 GIL 确保同一时间只有一个线程执行 Python 字节码,因此多线程在 CPU 密集型任务中性能提升有限。
多线程编程
Python多线程依赖threading模块实现
import threading
thread_obj = threading.Thread([group[, target, name, args, kwargs]])
"""
创建线程
params:
group: 指定进程组, 无进程组则是None
target: 执行的目标任务名
name: 线程名(可选)
args: 以元组的方式给执行任务传参
kwargs: 以字典方式给执行任务传参
"""
# 启动线程, 让线程开始工作
thread_obj.start()示例1: 直接创建线程
import threading
import time
def task(name):
print(f"任务 {name} 开始")
time.sleep(2) # 模拟耗时操作
print(f"任务 {name} 结束")
# 创建线程
thread1 = threading.Thread(target=task, args=("A",))
thread2 = threading.Thread(target=task, args=("B",))
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
print("所有任务完成")示例2: 继承 threading.Thread 类
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(f"任务 {self.name} 开始")
time.sleep(2) # 模拟耗时操作
print(f"任务 {self.name} 结束")
# 创建线程
thread1 = MyThread("A")
thread2 = MyThread("B")
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
print("所有任务完成")网络编程
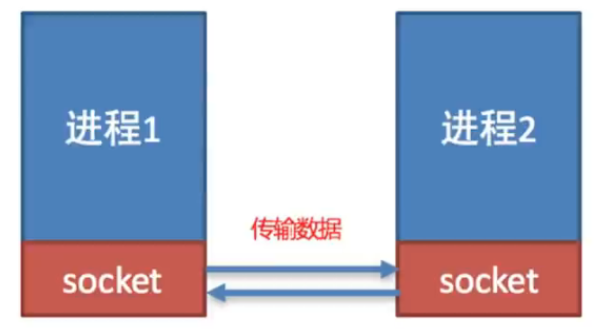
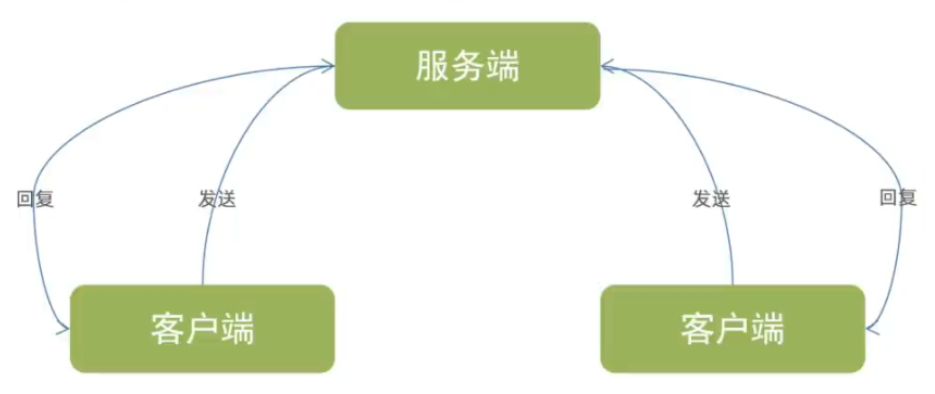
套接字(Socket)
Python 的 socket 模块提供了对网络通信的低级接口,允许你实现网络应用程序,如客户端-服务器模型。 它支持两种主要的协议:
- TCP(传输控制协议) : 面向连接,可靠,基于字节流
- UDP(用户数据报协议) : 无连接,不可靠,基于数据报
TCP Socket编程
- 服务器端:
- 创建Socket。
- 绑定IP地址和端口
- 监听连接
- 接受客户端连接
- 发送和接收数据
- 关闭连接
import socket
# 创建 TCP socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定 IP 和 端口
server_socket.bind('127.0.0.1', 12345)
# 监听连接
server_socket.listen(5) # 参数为允许连接的数量, 不填则自动设置
print("服务器已启动, 等待连接...")
# 接收客户端连接
client_socket.send("你好,客户端!".encode('utf-8'))
# 关闭连接
client_socket.close()
server_socket.close()- 客户端:
- 创建Socket
- 绑定IP地址和端口
- 接收数据
- 发送数据
- 关闭Socket
import socket
# 创建 TCP socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到服务器
client_socket.connet('127.0.0.1', 12345)
# 发送数据
client_socket.send("你好,服务器!".encode('utf-8'))
# 接收数据
data = client_socket.recv(1024)
print(f"收到数据: {data.decode('utf-8')}")
# 关闭连接
client_socket.close()UDP Socket编程
- 服务器端:
- 创建Socket
- 绑定IP地址和端口
- 接收数据
- 发送数据
- 关闭套接字
import socket
# 创建 UDP socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定 IP 和 端口
server_socket.bind(('127.0.0.1', 12345))
print("UDP 服务器已启动, 等待数据...")
# 接收数据
data, addr = server_socket.recvfrom(1024)
print(f"收到来自 {addr} 的数据: {data.decode('utf-8')}")
# 发送数据
server_socket.sendto("你好, 客户端!".encode('utf-8'), addr)
# 关闭socket
server_socket.close()- 客户端:
- 创建套接字
- 发送数据
- 接受数据
- 关闭套接字
import socket
# 创建 UDP 套接字
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 发送数据
client_socket.sendto("你好, 服务器!".encode(utf-8), ('127.0.0.1', 12345))
# 接收数据
data, addr = client_socket.recvfrom(1024)
print(f"收到来自 {addr} 的数据: {data.decode{'urf-8'}}")
# 关闭套接字
client_socket.close()正则表达式
Python 的正则表达式通过 re 模块提供支持,用于匹配、查找、替换和分割字符串。
正则表达式由普通字符和特殊字符(元字符)组成。以下是一些常用的元字符:
| 元字符 | 描述 |
|---|---|
. | 匹配任意字符 |
^ | 匹配字符串开头 |
$ | 匹配字符串结尾 |
* | 匹配前一个字符0次或多次 |
+ | 匹配前一个字符1次或多次 |
? | 匹配前一个字符0次或1次 |
{n} | 匹配前一个字符n次 |
{n,} | 匹配前一个字符至少n次 |
{n, m} | 匹配前一个字符至少n次, 至多m次 |
\d | 匹配数字, 等价于[0-9] |
\D | 匹配非数字 |
\w | 匹配字母、数字或下划线(等价于[a-zA-z0-9_]) |
\W | 匹配非字母、数字或下划线 |
\s | 匹配空白字符 |
\S | 匹配非空白字符 |
[] | 匹配括号内任意一个字符 |
` | 匹配左边或右边的表达式 |
() | 分组, 捕获匹配的内容 |
re模块的常用函数
re.match(): 从字符串的开头匹配正则表达式
import re
result = re.match(r'\d+', '123abc')
if result:
print("匹配成功:", result.group()) # 输出: 匹配成功: 123
else:
print("匹配失败")re.search(): 在字符串中搜索匹配正则表达式的第一个位置
import re
result = re.research(r'\d+', 'abc123def')
if result:
print("匹配成功:", result.group()) # 输出: 匹配成功: 123
else:
print("匹配失败")re.findall(): 查找字符串中所有匹配正则表达式的内容, 返回列表
import re
result = re.findall(r'\d+', 'abc123def456')
print(result) # 输出: ['123', '456']re.finditer(): 查找字符串中所有匹配正则表达式的内容, 返回迭代器
import re
result = re.finditer(r'\d+', 'abc123def456')
for match in result:
print(match.group())
# 输出:
# 123
# 456re.sub(): 替换字符串中匹配正则表达式的内容
import re
result = re.sub(r'\d+', 'NUM', 'abc123def456')
print(result) # 输出: abcNUMdefNUMre.split(): 根据正则表达式分割字符串, 返回列表类型
import re
result = re.split(r'\d+', 'abc123def456ghi')
print(result) # 输出: ['abc', 'def', 'ghi']正则表达式的分组
使用()可以将匹配的内容分组, 并通过group()方法获取
import re
result = re.search(r'(\d+)-(\d+)', '电话: 123-456')
if result:
print("完整匹配", result.group()) # 输出: 123-456
print("第一组", result.group(1)) # 输出: 123
print("第二组", result.group(2)) # 输出: 456贪婪匹配与非贪婪匹配
- 贪婪匹配 :
re模块的大部分函数默认为贪婪匹配, 正则表达式会尽可能多地匹配字符 - 非贪婪匹配 : 在量词后加
?, 尽可能少地匹配字符
import re
# 贪婪匹配
result = re.search(r'\d+', '123abc456')
print(result.group()) # 输出: 123
# 非贪婪匹配
result = re.search(r'\d+?', '123abc456')
print(result.group()) # 输出: 1常用正则表达式示例
- 匹配邮箱地址
import re
email = "example@domain.com"
pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
if re.match(pattern, mail):
print("email correct!")
else:
print("email error!")- 匹配手机号码
import re
phone = "13800138000"
pattern = r'^1[3-9]\d{9}$'
if re.match(pattern, phone):
print("phone number correct!")
else:
print("phone number error!")- 提取HTML标签中的内容
import re
html = "<div>内容</div>"
pattern = r'<[^>]+>(.*?)</[^>]+>'
result = re.search(pattern, html)
if result:
print("提取到内容:\n", result.group()) # 输出: 内容注意事项
- 正则表达式的性能可能受模式复杂度的影响,尽量避免过于复杂的模式
- 在处理大量数据时, 建议预编译正则表达式以提高性能:
import re
data = "待匹配的字符串"
pattern = re.compile(r'\d+') # 预编译正则表达式
retult = pattern.findall(data)递归
递归的基本概念
- 递归函数: 一个函数在其定义中调用自身
- 递归条件:
- 基线条件(Base Case): 递归终止的条件, 防止无限递归
- 递归条件(Recursive Case): 将问题分解为更小的子问题, 并调用自身解决
递归的基本结构
def recursive_func(参数):
if 基线条件:
return 基线结果
else:
更新参数
return recursive_func(更新后的参数)递归的经典示例
- 计算阶乘 阶乘的定义是:
n! = n * (n - 1), 其中0! = 1
def factorial(n):
if n == 0: # 基线条件
return 1
else:
return factorial(n * (n-1))- 计算斐波那契数列 斐波那契数列的定义是:
F(n) = F(n-1) + F(n-2), 其中F(0) = 0,F(1) = 1
def fibonacci():
if n == 0:
return 0
elif n == 1:
return 1
else:
return fabonacci(n-1) + fabonacci(n-2)- 遍历目录下的所有文件
- 基线条件: 如果是文件, 打印路径
- 递归条件: 如果是目录, 递归调用
import os
def list_file(path):
for item in os.listdir(path):
full_path = os.path.join(path, item)
if os.path.isdir(full_path): # 如果是目录, 递归调用
list_files(full_path)
else: # 如果是文件, 打印路径
print(full_path)递归的优缺点
优点 :
- 代码简洁: 递归可以用较少的代码解决复杂问题
- 直观: 对于树形结构, 递归的实现更符合问题的自然描述
缺点 :
- 性能问题: 递归可能产生大量的函数调用, 导致栈溢出或效率低下
- 调试困难: 递归的调用链较长时, 调试和跟踪问题可能比较困难
递归的优化
- 尾递归优化
尾递归是指递归调用是函数的最后一步操作。某些编程语言支持尾递归优化, 但Python不支持 - 记忆化
通过缓存已计算的结果, 避免重复计算
def fibonacci(n, memo = {}):
if n in memo: # 如果结果已缓存, 直接返回结果
return memo[n]
if n == 0: # 基线条件
return 0
elif n == 1: # 基线条件
return 1
else: #递归条件
memo[n] = fibonacci(n-1, memo) + fibonacci(n-2, memo)
return memo[n]- 转换为迭代
将递归问题转换为循环问题, 避免栈溢出
def factorial(n):
"""
计算n的阶乘
params:
n(int): 待计算的数
return:
result(int): n的阶乘
"""
result = 1
for i in range(1, n + 1):
result *= i
return result注意事项
- 栈溢出: Python默认的递归深度是1000, 可以通过sys.setrecursionlimit()修改, 但不建议滥用
- 基线条件: 必须确保递归有终止条件, 否则会无限递归
对象自省机制
Python 的对象自省机制是指在运行时动态获取对象信息的能力。通过自省,可以查看对象的类型、属性、方法等信息。
查看对象的类型
使用type()函数可以获取对象的类型
x = 42
print(type(x)) # 输出: <class 'int'>查看对象的所有属性和方法
使用dir()函数可以查看对象的所有属性和方, 返回列表
my_list = [1, 2, 3]
print(dir(my_list)) # 输出: ['__add__', '__class__', '__contains__', ...]使用__dict__属性可以查看对象的所有属性, 返回字典
class MyClass:
def __init__(self):
self.x = 10
self.y = 20
obj = MyClass()
print(obj.__dict__) # 输出: {'x': 10, 'y': 20}检查对象是否包含指定属性或方法
使用hasattr()函数可以检查对象是否包含指定属性或方法
class MyClass:
def __init__(self):
self.value = 10获取对象的属性或方法
使用getattr()函数可以获取对象的属性或方法
class MyClass:
def __init__(self):
self.value = 10
obj = MyClass()
print(getattr(obj, 'value')) # 输出: 10设置对象的属性值
使用setattr()函数可以设置对象的属性值
class MyClass:
def __init__(self):
self.value = 10
obj = MyClass()
setattr(obj, 'value', 20)
print(obj.value) # 输出: 20检查对象是否为某个类的实例
使用isinstance()函数可以检查对象是否为某个类的实例
class MyClass:
pass
obj = MyClass()
print(isinstance(obj, MyClass)) # 输出: True
print(isinstance(obj, str)) # 输出: False检查一个类是否是另一个类的子类
使用issubclass()函数可以检查一个类是否是另一个类的子类
class Parent:
pass
class Child(Parent):
pass
print(issubclass(Child, Parent)) # 输出: True
print(issubclass(Parent, Child)) # 输出: False(文章结束, 持续更新...)